KAIST
BREAKTHROUGHS
Research Webzine of the KAIST College of Engineering since 2014
Spring 2026 Vol. 26Text Teaches Vision Through Weakly Supervised Multimodal Framework for Accident Detection
TIME-VAD introduces a novel multi-modal framework combining text and vision for vehicle accident detection using weakly supervised learning with video-level labels only. Achieving 94.44% accuracy, the system provides frame-accurate detection and earlier anticipation than existing methods, advancing real-time traffic safety systems.

TIME-VAD framework (top): Text-informed magnitude enhancement with color-coded paths showing accident (red) and normal (purple) processing streams, utilizing CLIP features and contrastive learning. Qualitative comparison (bottom): TIME-VAD demonstrates genuine anticipation with probability rising only as danger emerges (frame 15), while existing models (DSTA/GCRNN) incorrectly predict high accident probability from the first frame.
Vehicle accidents remain a critical threat to road safety worldwide, demanding innovative solutions for early detection and prevention. Traffic surveillance systems and advanced driver assistance systems (ADAS) require accurate, real-time accident detection capabilities. However, existing approaches face significant challenges in handling complex traffic scenarios and distinguishing genuine accident precursors from normal driving patterns.
Researchers at Vehicular Intelligence Lab (VIL, KAIST) have developed Text-Informed Magnitude Enhancement for Vehicle Accident Detection (TIME-VAD), a groundbreaking framework that addresses these challenges through innovative multi-modal learning. Unlike conventional vision-only systems, TIME-VAD harnesses the power of both visual and textual information to achieve superior accident detection performance.
The key innovation lies in leveraging text to better represent accident concepts. The system uses textual anchors like "scene with collision" and "scene with accident" for accident scenarios, contrasted with "smooth traffic flow" and "routine daily commute" for normal driving. Through contrastive learning, the framework learns to distinguish accident features more effectively than image-based methods alone. Surprisingly, the research revealed that accident frames in CLIP embeddings exhibit lower feature magnitudes than normal frames, contradicting traditional assumptions and leading to a novel magnitude-enhanced learning strategy.
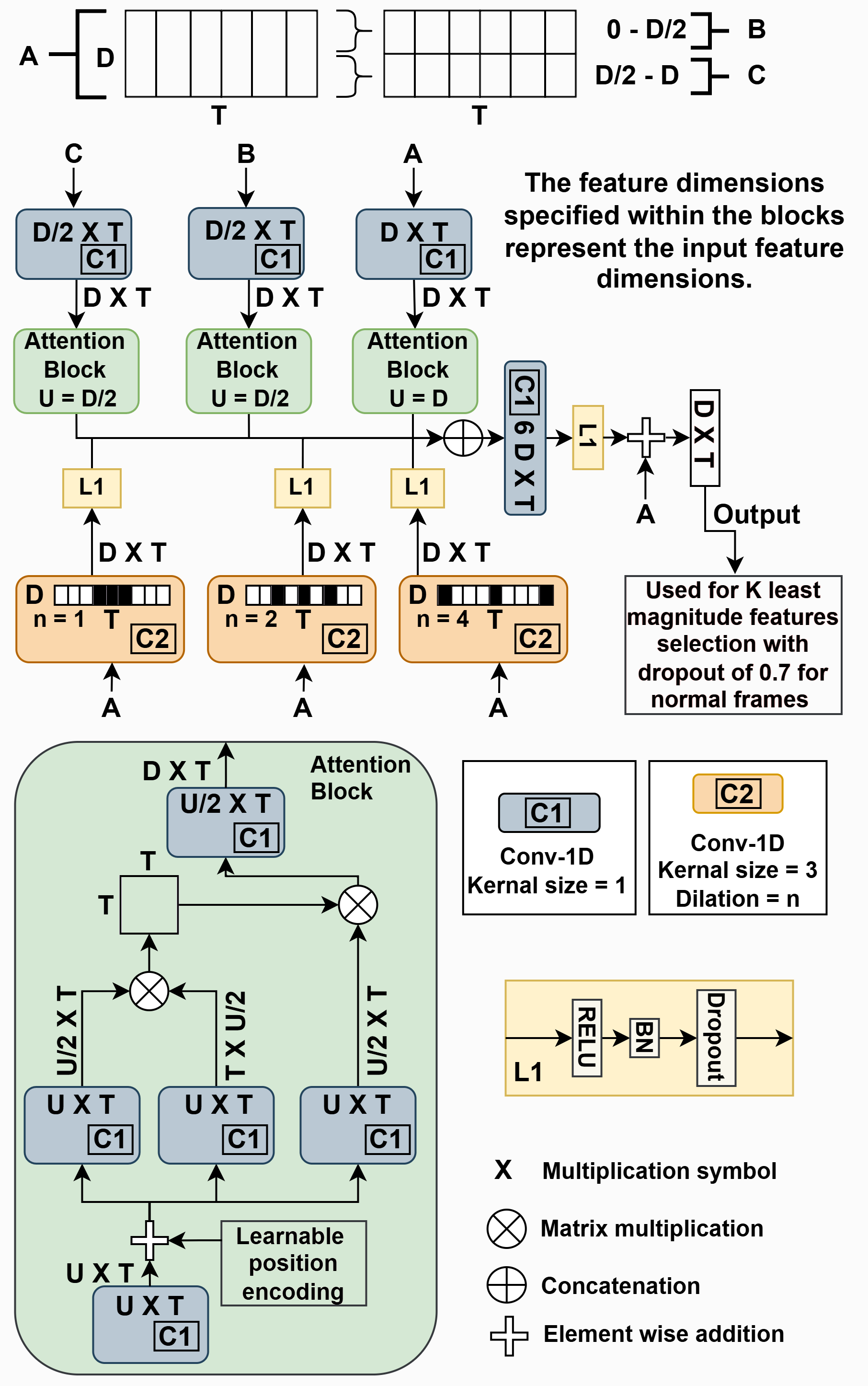
Figure 1. Dilated Temporal Conv-Attention (DTCA) Block
TIME-VAD introduces a Dilated Temporal Conv-Attention (DTCA) block that captures both local and global temporal dependencies in traffic videos. The framework employs weakly supervised multiple instance learning, requiring only video-level labels during training rather than frame-by-frame annotations of accident occurrence. This practical approach makes the system trainable without expensive frame-level ground truth labels for accidents.
Extensive evaluation on three benchmark datasets demonstrates TIME-VAD's superiority. On the DoTA dataset, containing 4,677 accident videos, the framework achieves 94.44% accuracy (ROC-AUC), significantly outperforming the previous best supervised model's 84.7%. Crucially, TIME-VAD provides accurate frame-level predictions despite being trained only with video-level labels. A key advantage is revealed through both quantitative frame-level metrics and qualitative analysis, which shows existing state-of-the-art models overfit to scene context and incorrectly predict high accident probability from the very first frame in videos containing accidents. In contrast, TIME-VAD demonstrates genuine frame-accurate anticipation, identifying when accidents become imminent and predicting them before they occur. The system achieves 99.97% average precision with a mean time-to-accident of 4.99 seconds on the CCD dataset.
The practical implications are substantial. TIME-VAD can be integrated into CCTV surveillance systems for citywide accident monitoring and emergency response coordination. For ADAS applications, the early detection capability enables vehicles to warn drivers or trigger automatic emergency braking systems before accidents occur. The framework's ability to generalize across different traffic scenarios, demonstrated through cross-dataset testing, makes it particularly suitable for real-world deployment.
This research advances traffic accident detection from reactive to proactive safety systems, potentially saving lives through earlier intervention and more accurate detection. The successful integration of language and vision opens new directions for AI-powered transportation safety systems.
Source: Mishra et al., "TIME-VAD: Text-Informed Magnitude Enhancement Feature Learning for Vehicle Accident Detection and Anticipation," IEEE Transactions on Intelligent Transportation Systems (2025)
Most Popular

Lighting the Lunar Night: KAIST Develops First Electrostatic Power Generator for the Moon
Read more
Soft Airless Wheel for A Lunar Exploration Rover Inspired by Origami and Da Vinci Bridge Principles
Read more
GPU-NPU-PIM Integration Technology for Generative AI Clouds
Read more
Dual-Action Hydrogel Offers New Hope for Rheumatoid Arthritis Treatment
Read more
Title WSF1 Vision Concept: Redefining Wearable Robotics through Human-centred Mobility Design
Read more