KAIST
BREAKTHROUGHS
Research Webzine of the KAIST College of Engineering since 2014
Spring 2025 Vol. 24AI updates itself by selecting and augmenting the data it trains on
The KAIST Data Intelligence Lab developed a new data-centric machine learning framework called RC-Mixup to train models so that they are robust against noisy and insufficient data on regression tasks.

Ph.D. students Seong-Hyeon Hwang and Minsu Kim from the KAIST Data Intelligence Lab, led by Prof. Steven Euijong Whang, have developed a new data-centric machine learning framework with which to train models so that they are robust against noisy and insufficient data on regression tasks. This framework significantly enhances the performance of regression models against noisy data compared to those in prior works.
As deep learning is employed in various regression applications such as smart manufacturing, climate prediction, and finance, obtaining large-scale training data is now essential to ensure the training of robust models. However, collecting vast amounts of training data can be challenging because doing so is expensive and may require significant domain knowledge. To address this issue, data augmentation techniques have been proposed to enhance the generalization of trained models by generating new data based on the distribution of existing data. While most data augmentation techniques are designed for classification tasks, a recent technique called C-Mixup was proposed to augment data for regression tasks by mixing pairs of samples that have close label distances using linear interpolation.
Simultaneously, robustness against noise is becoming increasingly critical for regression tasks. For instance, in semiconductor manufacturing, predicting the layer thickness in 3D semiconductors is crucial for defect detection. Noisy labels, caused by erroneous or malfunctioning measurement equipment, can degrade the performance of prediction models and negatively impact revenue. To address this challenge, recent approaches involve multi-round robust training, where noisy samples are removed or corrected based on their loss values through multiple training iterations.
Thus, the research team has proposed a novel data-centric framework called RC-Mixup, which integrates a data augmentation method (C-Mixup) and robust training methods to achieve a synergistic effect. RC-Mixup is the first framework designed to generate new data under noisy conditions for regression tasks. By leveraging robust training methods, RC-Mixup enhances the ability of the model to identify and handle noisy samples more effectively. Conversely, robust training also benefits from data augmentation, as a model trained on cleaner data produces better results, thereby improving the overall model performance.
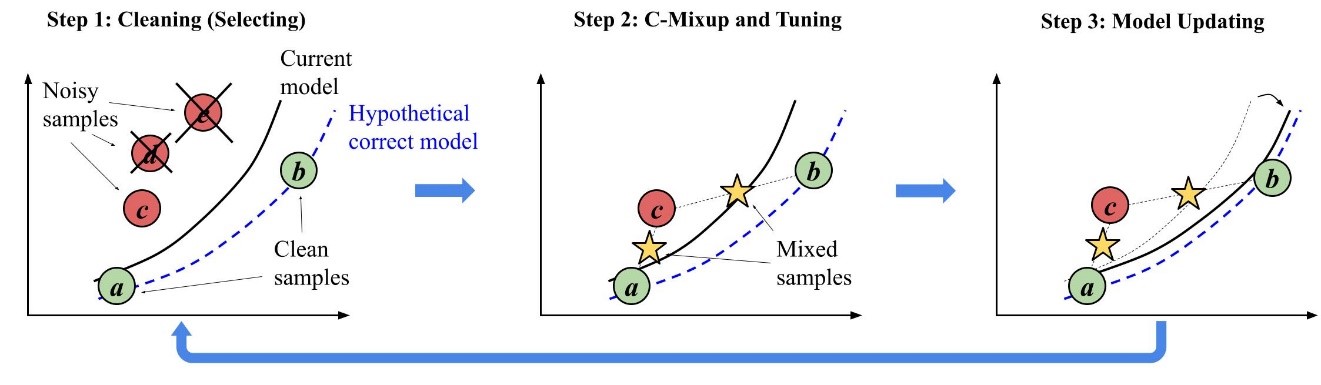
The research team observed an explicit relationship between the use of C-Mixup and the data noise ratio. To improve the performance of the model, samples must be mixed with more distant neighbors as the noise ratio increases. Because robust training methods reduce the noise ratio during training, RC-Mixup can achieve better performance by adjusting the bandwidth parameter, which determines the range of neighbors to mix. The optimal bandwidth is periodically selected from a range of candidates based on the performance on a validation set. As a result, RC-Mixup significantly enhances the performance of regression models against noisy data. Additionally, the team proposed a bandwidth decaying method as an alternative tuning approach, offering faster training speeds while maintaining better performance compared to baseline methods.
This research will be published under the title "RC-Mixup: A Data Augmentation Strategy against Noisy Data for Regression Tasks" at the ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) 2024, the top conference in data science and data mining.
Most Popular

When and why do graph neural networks become powerful?
Read more
Smart Warnings: LLM-enabled personalized driver assistance
Read more
Extending the lifespan of next-generation lithium metal batteries with water
Read more
Professor Ki-Uk Kyung’s research team develops soft shape-morphing actuator capable of rapid 3D transformations
Read more
Oxynizer: Non-electric oxygen generator for developing countries
Read more