KAIST
BREAKTHROUGHS
Research Webzine of the KAIST College of Engineering since 2014
Fall 2025 Vol. 25AI self-learns to discover the structure of the world like humans
One of the long-desired goals of machine learning is to develop a human-like self-supervised learning algorithm that can learn the object-centric world structure just by seeing the pixels of complex scenes. A collaboration project between KAIST and Rutgers University succeeded in this challenge for the first time in this line of research.
Article | Spring 2023
Understanding a visual scene is the most crucial function of the human brain and also a core ability of AI, particularly for its vision-based applications such as robots, self-driving cars, and smart homes. However, understanding such visual scenes in AI is a notorious challenge. In the real world, one encounters object types that are almost infinitely diverse, many of which have not been seen before. Moreover, a scene is a complex composition of many such objects.
Due to these difficulties, current AI technology relies on human annotations to learn what an object is. Given an image, humans collect labels for objects such as location, boundary, and class. An AI is then trained to make predictions as close to these human labels as possible. However, this approach, known as supervised learning, comes with many limitations, such as high labeling cost, high labeling error, and a lack of label adaptability.
Furthermore, this process differs greatly from how humans learn to see the object-centric world. Research on developmental cognitive science suggests that infants develop core knowledge about objects during the first few months after birth. A baby self-learns the ability just by seeing the world (and, of course, by touching and tasting). In general, human learning about objects is not supervised unlike AI. Such self-supervised learning of humans is much more cost-effective than supervised learning of AI and gives the ability to adapt object representations to various contexts dynamically.
As such, one of the long-desired dreams of machine learning, computer vision, and cognitive science has been to develop a human-like self-supervised learning algorithm that can learn the object-centric structure of the world just by seeing the pixels. However, until recently, achieving this for complex and naturalistic scenes seemed quite elusive.
An international team of researchers from KAIST and Rutgers University has recently made a breakthrough in this challenging problem. The joint research team led by Prof. Sungjin Ahn succeeded in developing the world’s first unsupervised object-centric learning algorithm for complex visual scenes.
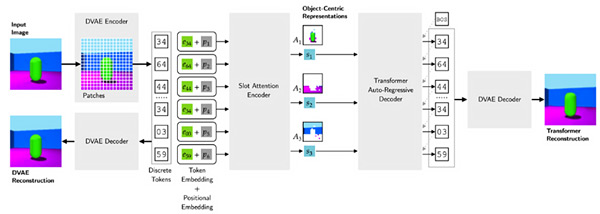
The key idea behind this success is to introduce a highly-flexible decoder in the slot-based encoder-decoder architecture, as shown in Figure 1. According to Prof. Ahn, this attempt is interesting because researchers in the community have long believed that they should not or cannot use such a flexible decoder if they wanted to encourage the emergence of unsupervised object representations. This belief was due to slot degeneration, a problem where an object representation models the whole scene instead of only one object.
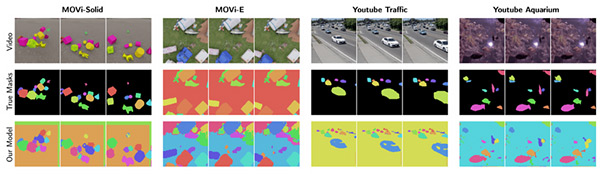
Inspired by DALLE, a language-to-image generation model, the research team has hypothesized that a transformer-based decoder conditioning on the object slots would not suffer from the slot degeneration problem and proposed the SLATE model and its extension to videos called STEVE. In experiments, the team demonstrated how the model works on complex natural videos for the first time in this line of research and showed that the proposed model significantly outperforms the previous approaches as shown in Figure 2.
As Prof. Ahn stated “this technology has the potential to change the way AI has approached the problem of vision for the past several decades because the new method is unsupervised like human learning.” He added, “for a broad range of visual AI applications, it will help reduce both cost and error while also opening opportunities to novel applications that can learn what an object is more adaptively.”
References
1. Gautam Singh, Yi-Fu Wu, Sungjin Ahn, Simple Unsupervised Object-Centric Learning for Complex and Naturalistic Videos, Neural Information Processing Systems 2022
2. Gautam Singh, Fei Deng, Sungjin Ahn, Illiterate DALLE Learns to Compose, International Conference on Learning Representations, 2022
Most Popular

A New solution enabling soft growing robots to perform a variety of tasks in confined spaces
Read more
Towards a more reliable evaluation system than humans - BiGGen-Bench
Read more
Development of a compact high-resolution spectrometer using a double-layer disordered metasurface
Read more
AI-Designed carbon nanolattice: Feather-light, steel-strong
Read more
Dual‑Mode neuransistor for on‑chip liquid‑state computing
Read more